TPC-H是事务处理性能委员会( Transaction ProcessingPerformance Council )制定的基准程序之一,TPC- H 主要目的是评价特定查询的决策支持能力,该基准模拟了决策支持系统中的数据库操作,测试数据库系统复杂查询的响应时间,以每小时执行的查询数(TPC-H QphH@Siz)作为度量指标。我们在很多大数据系统上线或者产品上线的时候一般都会测 w397090770 3年前 (2021-10-29) 1603℃ 0评论5喜欢
这次整理的PPT来自于2017年04月10日至11日在San Francisco进行的flink forward会议,这种性质的会议和大家熟知的Spark summit类似。本次会议的官方日程参见:http://sf.flink-forward.org/kb_day/day1/。因为原始的PPT是在http://www.slideshare.net/网站,这个网站需要翻墙;为了学习交流的方便,这里收集了本次会议所有课下载的PPT(共27个),希望对大家有所 w397090770 8年前 (2017-04-20) 2766℃ 0评论8喜欢
Hadoop自升级到2.x版本之后,有很多属性的名称已经被遗弃了,虽然这些被遗弃的属性名称目前还可以用,但是这里还是建议用新的属性名,主要遗弃的属性名称主要见下面表格:已经被遗弃属性的名称新的属性名称create.empty.dir.if.nonexistmapreduce.jobcontrol.createdir.ifnotexistdfs.access.time.precisiondfs.namenode.accesstime.prec w397090770 11年前 (2014-02-13) 17373℃ 0评论10喜欢
杭州第六次 Spark & Flink Meetup 于2018年05月12日在华为杭研所1号楼1楼报告厅进行。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop议题本次会议的议题如下:冯叶磊 - 华为云 《Time GeoSpatial on Flink SQL》范文臣 - Spark PMC 《deep dive into structural streaming》梁永峰 - 阿里《基于Flink的流计算平台 w397090770 6年前 (2018-05-13) 3926℃ 1评论8喜欢
在《HDFS 快照编程指南》文章中,我简单介绍了 HDFS 的快照功能。本文将介绍 HBase 快照功能,因为 HBase 的底层存储是基于 HDFS 的,所以 HBase 的快照功能也是依赖 HDFS 快照的知识。HBase 快照功能是从 HBase 0.95.0 开始引入的,详见 HBASE-50。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoopHBase 快 w397090770 6年前 (2019-01-01) 2637℃ 0评论9喜欢
背景随着 Apache HBase 在各个领域的广泛应用,在 HBase 运维或应用的过程中我们可能会遇到这样的问题:同一个 HBase 集群使用的用户越来越多,不同用户之间的读写或者不同表的 compaction、region splits 操作可能对其他用户或表产生了影响。将所有业务的表都存放在一个集群的好处是可以很好的利用整个集群的资源,只需要一套运 w397090770 6年前 (2018-11-01) 6434℃ 4评论13喜欢
Hadoop的一大基本原则是移动计算的开销要比移动数据的开销小。因此,Hadoop通常是尽量移动计算到拥有数据的节点上。这就使得Hadoop中读取数据的客户端DFSClient和提供数据的Datanode经常是在一个节点上,也就造成了很多“Local Reads”。最初设计的时候,这种Local Reads和Remote Reads(DFSClient和Datanode不在同一个节点)的处理方式都是一 w397090770 6年前 (2018-07-22) 99℃ 0评论0喜欢
什么是SSH?Secure Shell(缩写为SSH),由IETF的网络工作小组(Network Working Group)所制定;SSH为一项创建在应用层和传输层基础上的安全协议,为计算机上的Shell(壳层)提供安全的传输和使用环境。传统的网络服务程序,如rsh、FTP、POP和Telnet其本质上都是不安全的;因为它们在网络上用明文传送数据、用户帐号和用户口令,很容 w397090770 11年前 (2013-10-22) 8709℃ 3评论2喜欢
最近升级了 WordPress,但是出现了以下的异常:[code lang="bash"]Your server is running PHP version 5.4.16 but WordPress 5.4.4 requires at least 5.6.20.[/code]可见 WordPress 5.4.4 版本需要 PHP 5.6.20 及以上才可以正常运行,所以本文记录 PHP 的升级过程。检查当前安装的 PHP我们可以使用下面命令看下当前服务器上的 PHP 版本[code lang="bash"][root@iteblog.com w397090770 4年前 (2020-10-06) 323℃ 0评论0喜欢
本博客分享的其他视频下载地址:《传智播客Hadoop实战视频下载地址[共14集]》、《传智播客Hadoop课程视频资料[共七天]》、《Hadoop入门视频分享[共44集]》、《Hadoop大数据零基础实战培训教程下载》、《Hadoop2.x 深入浅出企业级应用实战视频下载》、《Hadoop新手入门视频百度网盘下载[全十集]》 本博客收集到的Hadoop学习书 w397090770 10年前 (2014-07-15) 92406℃ 0评论164喜欢
最近由Reynold Xin给Spark开发者发布的一封邮件透露,Spark社区很有可能会跳过Spark 1.7版本的发布,而直接转向Spark 2.x。 如果Spark 2.x发布,那么它将: (1)、Spark编译将默认使用Scala 2.11,但是还是会支持Scala 2.10。 (2)、移除对Hadoop 1.x的支持。不过也有可能移除对Hadoop 2.2以下版本的支持,因为Hadoop 2.0和2.1版本分 w397090770 9年前 (2015-11-13) 6983℃ 0评论16喜欢
本博客收集的手机号段截止时间为2020年03月的,共计450000+条。包含以下字段:电信:133 153 173(新) 177 (新) 180 181 189 199 (新)移动:134 135 136 137 138 139 150 151 152 157 158 159 172(新) 178(新) 182 183 184 187 188 198(新) 联通:130 131 132 155 156 166(新) 175(新) 176(新) 185 186数据卡:145 147 149其他:170(新) 171 (新)API地址/api/mobile.php使用本AP w397090770 8年前 (2016-08-02) 5075℃ 0评论15喜欢
程序的问题:已知数组a[n],求数组b[n].要求:b[i]=a[0]*a[1]*……*a[n-1]/a[i],不能用除法。a.时间复杂度O(n),空间复杂度O(1)。 b.除了迭代器i,不允许使用任何其它变量(包括栈临时变量等)大家有什么解法?先不要看我下面的解法。希望大家讨论讨论一下,留个言,一起交流一下。下面给出我的解法一:[code lang="CPP"]#include <stdio. w397090770 12年前 (2013-04-03) 4252℃ 0评论3喜欢
使用MEMORY_ONLY储存级别对RDD进行缓存,其内部实现是调用persist()函数的。官方文档定义:Persist this RDD with the default storage level (`MEMORY_ONLY`).函数原型[code lang="scala"]def cache() : this.type[/code]实例[code lang="scala"]/** * User: 过往记忆 * Date: 15-03-04 * Time: 下午06:30 * bolg: * 本文地址:/archives/1274 * 过往记忆博客, w397090770 10年前 (2015-03-04) 14185℃ 0评论8喜欢
Linux(vi/vim)一般模式语法功能描述yy复制光标当前一行y数字y复制一段(从第几行到第几行)p箭头移动到目的行粘贴u撤销上一步dd删除光标当前行d数字d删除光标(含)后多少行x删除一个字母,相当于delX删除一个字母,相当于Backspaceyw复制一个词dw删除一个词 zz~~ 3年前 (2021-12-01) 168℃ 0评论0喜欢
Apache Kafka 是一个开源流处理平台,如今有超过30%的财富500强企业使用该平台。Kafka 有很多特性使其成为事件流平台(event streaming platform)的事实上的标准。在这篇博文中,我将介绍每个 Kafka 开发者都应该知道的五件事,这样在使用 Kafka 就可以避免很多问题。Tip #1 理解消息传递和持久性保证对于数据持久性(data durability), w397090770 3年前 (2021-04-18) 1006℃ 0评论4喜欢
导读:向量化技术带来极致的CPU效率的同时,也已经成为了软件开发的趋势,而数据库的向量化不仅仅是 CPU 指令的向量化,还是一个巨大的性能优化工程。本文从CPU向量化原理出发,通过Cache、虚函数、SIMD等方面讨论CPU的性能优化,介绍了Apache Doris现有列存行式计算结构向列存列式计算结构的转变,同时展示了目前Apache D w397090770 3年前 (2022-03-01) 1168℃ 0评论3喜欢
本文是对 Gilbert and Lynch's specification and proof of the CAP Theorem 文章的概括版本。大部分内容参照 An Illustrated Proof of the CAP Theorem 文章的。什么是 CAP 定理CAP 定理是分布式系统中的基本定理,这个理论表明任何分布式系统最多可以满足以下三个属性中的两个。一致性(Consistency)可用性(Availability)分区容错性(Partition tolerance w397090770 6年前 (2018-07-17) 2973℃ 1评论12喜欢
想必大家在使用Maven从仓库下载Jar的时候都感觉速度非常慢吧。前几年国内的开源中国还提供了免费的Maven镜像,但是由于运营成本过高,此Maven仓库在运营两年后被迫关闭了。不过高兴的是,阿里云在2016年08月悄悄上线了Maven仓库,点这里:http://maven.aliyun.com。我们可以把下面的配置复制到$MAVEN_HOME/conf/setting.xml里面:如果想及时 w397090770 8年前 (2017-02-16) 18302℃ 1评论6喜欢
课程讲师:Cloudy 课程分类:Java 适合人群:初级 课时数量:8课时 用到技术:Zookeeper、Web界面监控 涉及项目:案例实战 此视频百度网盘免费下载。本站所有下载资源收集于网络,只做学习和交流使用,版权归原作者所有,若为付费视频,请在下载后24小时之内自觉删除,若作商业用途,请购 w397090770 10年前 (2015-04-18) 34785℃ 2评论57喜欢
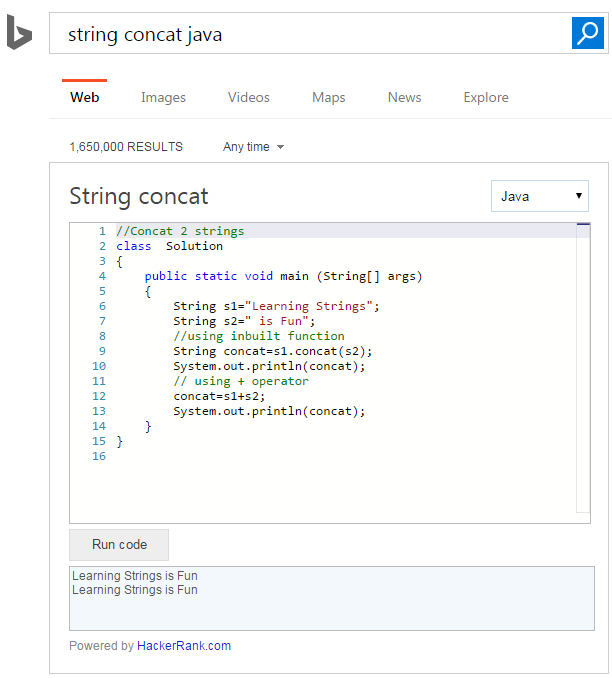
微软的搜索引擎Bing和HackerRank合作,在Bing的搜索结果里面加入了实时代码编辑器,它为数以百万计的程序员提供了一种简单的方法来搜索结果,主要是允许程序员在搜索结果中直接编辑和执行代码示例,实时查看运行结果。 通常情况下,工程师需要到Stackoverflow, Stackexchange或者其他的博客搜索他们需要的答案。现在我们有 w397090770 9年前 (2016-04-11) 1789℃ 0评论2喜欢
最近使用ElasticSearch的时候遇到以下的异常[code land="bash"]2017-07-27 16:06:48.482 MessageHandler - message process error: java.lang.NoClassDefFoundError: Could not initialize class org.elasticsearch.common.xcontent.smile.SmileXContent at org.elasticsearch.common.xcontent.XContentFactory.contentBuilder(XContentFactory.java:124) ~[elasticsearch-2.3.4.jar:2.3.4] at org.elasticsearch.action.support.ToX w397090770 7年前 (2017-07-27) 8601℃ 0评论13喜欢
本书书名全名:Learning Spark Streaming:Best Practices for Scaling and Optimizing Apache Spark,于2017-06由 O'Reilly Media出版,作者 Francois Garillot, Gerard Maas,全书300页。本文提供的是本书的预览版。关注大数据猿(bigdata_ai)公众号及时获取最新大数据相关电子书、资讯等通过本书你将学到以下知识Understand how Spark Streaming fits in the big pictureLearn c zz~~ 7年前 (2017-10-18) 6450℃ 0评论21喜欢
为了保存Scala和Java API之间的一致性,一些允许Scala使用高层次表达式的特性从批处理和流处理的标准API中删除。 如果你想体验Scala表达式的全部特性,你可以通过隐式转换(implicit conversions)来加强Scala API。 为了使用这些扩展,在DataSet API中,你仅仅需要引入下面类:[code lang="scala"]import org.apache.flink.api.scala.extensio w397090770 9年前 (2016-04-25) 3798℃ 0评论3喜欢
摘要:本文整理自 58 同城实时计算平台负责人冯海涛在 Flink Forward Asia 2020 分享的议题《Flink 在 58 同城应用与实践》,内容包括: 实时计算平台架实时 SQL 建设Storm 迁移 Flink 实践一站式实时计算平台后续规划如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据实时计算平台架构 w397090770 3年前 (2021-08-17) 286℃ 0评论2喜欢
即日起,关注@Spark技术博客 及@ 一位微博好友并转发本文章到微博有机会获取《Spark大数据分析实战》:/archives/1590。3月12日在微博抽奖平台抽取1位同学并赠送此书。本活动已经结束,抽奖信息已经在新浪微博抽奖平台公布 《Spark大数据分析实战》由高彦杰和倪亚宇编写,通过典型数据分析应用场景、算法与系统架构,结 w397090770 9年前 (2016-03-02) 8515℃ 0评论44喜欢
默认情况下,Flume中的PollingPropertiesFileConfigurationProvider会每隔30秒去重新加载Flume agent的配置文件,如果监听到配置文件变化了,Flume会试图重新加载变化的配置文件。判断配置文件是否变化主要是基于文件的最后修改时间来的,代码片段如下:[code lang="java"]///////////////////////////////////////////////////////////////////// User: 过往记忆 w397090770 9年前 (2015-08-20) 6667℃ 0评论13喜欢
本书于2017-05由Packt Publishing出版,作者Rishi Yadav,全书294页。从书名就可以看出这是一本讲解技巧的书。本书副标题:Over 70 recipes to help you use Apache Spark as your single big data computing platform and master its libraries。本书适合数据工程师,数据科学家以及那些想使用Spark的读者。阅读本书之前最好有Scala的编程基础。通过本书你将学到以下知识 zz~~ 7年前 (2017-07-07) 4842℃ 0评论16喜欢
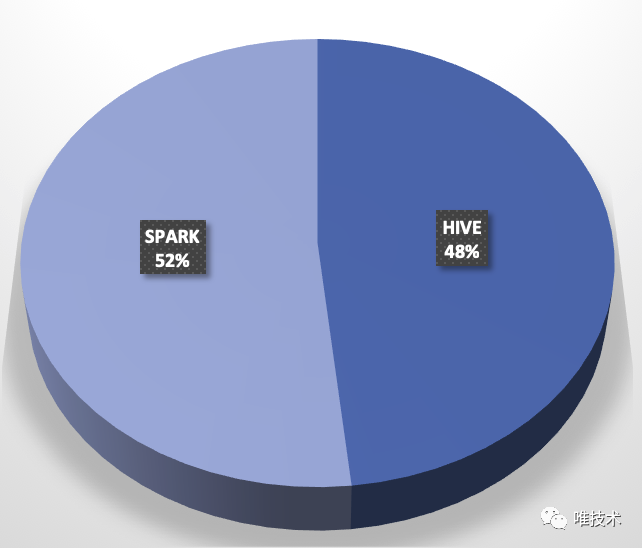
导读.bordered th, .bordered td{text-align:left;}唯品会离线平台SPARK2.3.2无缝升级到SPARK3.0.1版本,完全做到了对用户透明,目前正按着既定方案进行升级,新的版本SPARK CORE/SQL/PySpark进行了优化和BugFix,并且Merge了SPARK vip 2.3.2 重要Patch,在性能和易用性上比旧版本都有较大提升。这篇文章介绍了我们升级SPARK过程中遇到的挑战和思考, w397090770 4年前 (2021-04-05) 1264℃ 0评论4喜欢
在Spark 1.4中引入了REST API,这样我们可以像Hadoop中REST API一样,很方便地获取一些信息。这个ISSUE在https://issues.apache.org/jira/browse/SPARK-3644里面首先被提出,已经在Spark 1.4加入。 Spark的REST API返回的信息是JSON格式的,开发者们可以很方便地通过这个API来创建可视化的Spark监控工具。目前这个API支持正在运行的应用程序,也支持 w397090770 9年前 (2015-06-10) 15765℃ 0评论8喜欢














![[电子书]Learning Spark Streaming PDF下载](https://www.iteblog.com/pic/books/Learning_Spark_Streaming_iteblog.jpg)


![[电子书]Apache Spark 2.x Cookbook, 2nd Edition PDF下载](https://www.iteblog.com/pic/books/apache-spark-2x-cookbook_iteblog.png)